Tiered compilation for graph bytecode
Modelverse JIT
A tiered just-in-time compiler for graph-based bytecode, moving hot programs from interpretation to SSA-based optimization.
- Impact
- 37x speedup over reference implementation
- Role
- Built interpreter, baseline JIT, and optimizing SSA JIT
- Stack
- JIT · SSA · bytecode · runtime optimization
Technical story
How the system works
The Modelverse JIT was my undergraduate honors research project at the University of Antwerp, supervised by Yentl Van Tendeloo and Professor Hans Vangheluwe. It was also one of the first projects where I really had to think like a compiler engineer instead of someone merely generating code.
The source branch appears to have disappeared with time, which is a shame. The project report survived, though, and rereading it now is oddly charming: the prose is undergraduate-me, but the compiler problem was real. The Modelverse was a research virtual machine for multi-paradigm modelling. All data lived in a graph called the Modelverse State, and the Modelverse Kernel executed instructions that were themselves stored in that graph. That design made the system unusually self-descriptive and flexible, but it also made the reference interpreter very slow.
The interpreter implemented instructions as graph transformations. Even a constant instruction had to query the current stack frame, read and update graph edges, allocate a new phase node, delete old edges, and communicate repeatedly with the State. The report’s small example used ten Modelverse State requests just to make a constant become the current return value. That is semantically clean. It is also a lot of ceremony for something that a conventional VM would treat as one tiny operation.
The goal was to replace that reference Kernel with a drop-in tiered JIT while preserving the parts of the Modelverse execution model that mattered: graph-based data, cooperative server scheduling, garbage collection safepoints, and the ability to fall back to the reference interpreter for mutable functions.
Compiling a graph VM to Python
The target language was Python, which sounds funny for a JIT compiler until you look at the system boundary. The Modelverse implementation was already a Python server. Kernel functions communicated with the State through Python generators: yielding a request handed control back to the server, which performed the graph operation and resumed the Kernel. Generating Python source let the JIT stay inside that runtime architecture instead of introducing a native-code backend and a much harder integration problem.
The compilation target was not “Python because Python is fast.” It was Python because Python was the VM’s implementation substrate. The useful performance win came from removing Modelverse-level overhead: avoiding interpreter dispatch, replacing graph-backed interpreter data structures with ordinary Python variables where possible, bundling State requests, and doing classic optimization before producing generator functions.
The pipeline had three execution tiers:
Modelverse instruction graph
-> bytecode IR interpreter
-> baseline JIT to Python generator source
-> optimizing SSA JIT to Python generator sourceCold code could run in the bytecode IR interpreter. Warmer code could be compiled quickly by the baseline JIT. Hotter code could go through the optimizing JIT, which spent more compile time building and simplifying a control-flow graph in SSA form. Mutable functions, whose instruction graph might change without notifying the Kernel, stayed on the reference interpreter rather than making every call pay for expensive validation.
The first win was just using the right data structures
The bytecode IR interpreter was not a compiler in the code-generating sense. It pre-parsed Modelverse instruction graphs into a more direct bytecode representation, then interpreted that representation with specialized runtime data structures. That alone mattered.
For the constant instruction, the reference interpreter’s graph transformation became essentially:
self.update_result(instruction.constant_id)The point was not that every instruction became that simple. The point was that the original interpreter was paying graph-manipulation costs for its own bookkeeping. Stack frames, return values, instruction phases, and other interpreter-internal concepts did not always need to be represented as State graph edits during execution. Pre-parsing the instruction graph let the new interpreter replace many of those operations with Python object access.
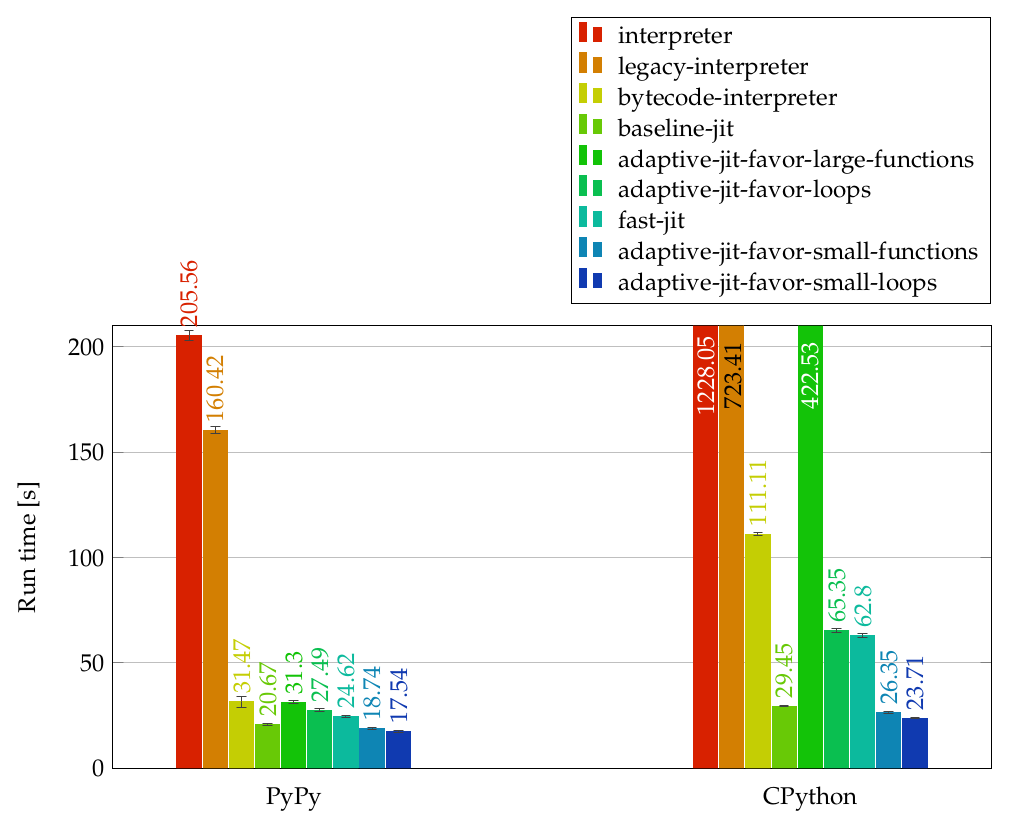
On the representative simulation benchmark in the report, that optimized interpreter was about 7.7x faster than the legacy interpreter. No deep optimization magic yet. Just moving bookkeeping out of the graph when the graph was the wrong place for it.
The baseline JIT erased the interpreter loop
The baseline JIT compiled bytecode IR into a tree IR and then emitted Python generator functions. Its job was to generate code quickly, so the optimizations were deliberately simple:
- constant folding,
- compile-time reads of immutable node values,
- replacement of well-known Modelverse intrinsics with direct operations,
- bundling independent Modelverse State requests into a single yield.
That last optimization was especially tied to the Modelverse architecture. Every State request crossed the Kernel/server boundary by unwinding and resuming generator frames. Combining independent requests reduced both Python generator overhead and communication with the State abstraction. It also left the design compatible with the more distributed Modelverse architecture, where the State could in principle live behind a network or database boundary.
Function calls needed their own runtime support. The old generator calling convention forwarded yields up and down the Python call stack, making a State request cost proportional to call depth. The JIT introduced a request handler with its own explicit generator stack. Calls, tail calls, exception handlers, debug information, and source maps became request-handler services. That brought State-request forwarding back to constant time and made generated stack traces point back into Modelverse source rather than only into compiler-generated Python.
This is one of the details I still like. It is not a glamorous optimization pass, but it is exactly the kind of runtime plumbing a JIT needs before the optimization story is allowed to matter.
The fast JIT made it a compiler
The fast JIT was the part where the project became recognizably compiler-shaped. It lowered bytecode IR into a control-flow graph whose basic blocks contained value definitions and block parameters. In other words, it used an SSA-like IR with block arguments instead of explicit phi instructions.
That representation made the Modelverse’s awkward local-variable semantics tractable. In the source language, resolving a name could produce a pointer to a local variable or a global value depending on which definitions were reachable along the current path. The fast JIT first represented that conservatively, then used dominance and reachability information to replace local-existence checks with constants when possible. Once those checks collapsed, ordinary flow simplification and block merging removed the branches that had only existed to preserve the dynamic lookup semantics.
The most important optimization was SSA construction for Modelverse locals. Source-level locals were represented indirectly as pointer nodes in the graph. The fast JIT detected locals whose pointers did not escape, then promoted their loads and stores into SSA values using a standard SSA construction algorithm. That turned common local-variable operations into ordinary Python local variables in the generated code.
For a tiny remainder function, the optimized fast-JIT code read both arguments, performed integer arithmetic directly, created one result node, and returned it. The baseline JIT version was still shuffling pointer nodes and value nodes through the State. That contrast captures the whole project: the winning move was to keep the graph semantics at the boundary while recovering conventional value semantics inside compiled code.
The fast JIT also included the sort of pass pipeline that makes a young compiler person grin:
flow simplification
local-definition check elision
block merging
trivial phi elimination
SSA construction for locals
direct-call recovery
data-structure optimizations
intrinsic expansion
compile-time reads
read commoning
constant folding
dead code elimination
GC root insertion and elisionSome passes ran more than once because they exposed opportunities for each other. The implementation was modest, but the idea was the real thing: choose an IR that makes the expensive semantics explicit, then gradually prove that much of the machinery is unnecessary for the common case.
Safepoints and roots were part of the compiler
Compiled Modelverse code could not simply run flat-out.
The server relied on periodic nop yields for task switching, I/O, and garbage collection.
The interpreter emitted a nop after each instruction phase, but that would have become a bottleneck in compiled code.
The JIT instead emitted nops on loop back-edges, where long-running programs were likely to spend their time.
That immediately created a compiler/runtime correctness problem.
If a compiled function created a node, hit a nop, and only used that node later, the Modelverse garbage collector might delete it unless the compiler had made it reachable from the State root.
So the JIT had to insert GC roots for values live across potential safepoints.
The fast JIT then performed a small root-elision analysis to remove roots for values whose definition and last use occurred without an intervening safepoint.
The adaptive JIT even exposed a calling-convention bug here. The baseline JIT and fast JIT protected function arguments differently: one naturally protected them in the callee, the other wanted protection at the call site. Mixing tiers left some arguments unprotected from GC until the convention was repaired. That is a deeply compiler-shaped bug: not “the generated code is obviously wrong,” but “two independently reasonable lowering contracts compose incorrectly at a runtime boundary.”
Tiering was a compile-time optimization
The adaptive JIT assigned each function a temperature. Cold functions used the bytecode interpreter, lukewarm functions used the baseline JIT, and hot functions used the fast JIT. Repeated calls increased temperature, so a function could climb through the tiers over time.
The interesting question was the initial temperature heuristic. I tried favoring large functions, small functions, loops, and small loops. The result was not what I expected from the Java JIT literature I had read. Favoring large functions performed poorly, partly because one of the fast JIT’s analyses had quadratic behavior and some Modelverse library functions contained very large loops that were expensive to compile. Favoring small functions and small loops worked better.
That lesson has aged well. Tier selection is not just about predicting which generated code will run fastest. It is also about predicting which compilation work is worth doing. The adaptive JIT’s job was to minimize total time: compile time plus run time. Sometimes the best compiler optimization is deciding not to optimize yet.
What changed
The best adaptive configuration reduced the representative mvc simulate benchmark from about 1292 seconds on the legacy interpreter to about 35 seconds including compilation time.
That is roughly a 37x speedup.
The speedup came in layers. The bytecode IR interpreter removed a large amount of graph-transformation overhead. The baseline JIT removed interpreter dispatch and bundled communication with the State. The fast JIT recovered local value semantics with SSA, simplified control flow, expanded intrinsics, and removed dead work. The adaptive JIT kept the optimizing compiler away from code where its compile-time cost was not justified.
It was still research infrastructure, and it had real limitations. The generated code lived in memory. The custom request handler made infinite recursion run into ordinary machine limits. A native backend, inlining, and more aggressive optimization would have been obvious next steps. But for the actual Modelverse workload, the core compiler idea held up: even when the target is Python and the source program is a graph of modelling-language instructions, classic compiler techniques still find leverage.
That is what I remember most fondly about the project. It taught me that optimization is often less about heroic cleverness than about restoring structure. Find the values hidden behind graph edges. Find the control flow hidden behind instruction nodes. Find the locals hidden behind pointer-like State objects. Once those shapes are visible, old compiler machinery becomes useful again.
You can download the project report here.